
 |  |
2.7. Caching
The whole resolution process may seem awfully convoluted and cumbersome to someone accustomed to simple searches through the host table. Actually, though, it's usually quite fast. One of the features that speeds it up considerably is caching.A name server processing a recursive query may have to send out quite a few queries to find an answer. However, it discovers a lot of information about the domain name space as it does so. Each time it's referred to another list of name servers, it learns that those name servers are authoritative for some zone, and it learns the addresses of those servers. And at the end of the resolution process, when it finally finds the data the original querier sought, it can store that data for future reference. With Version 4.9 and all Version 8 and 9 BINDs, name servers even implement negative caching: if an authoritative name server responds to a query with an answer that says the domain name or datatype in the query doesn't exist, the local name server will temporarily cache that information, too. Name servers cache all this data to help speed up successive queries. The next time a resolver queries the name server for data about a domain name the name server knows something about, the process is shortened quite a bit. If the name server has cached the answer, positive or negative, it simply returns the answer to the resolver. Even if it doesn't have the answer cached, it may have learned the identities of the name servers that are authoritative for the zone the domain name is in and be able to query them directly.
For example, say our name server has already looked up the address eecs.berkeley.edu. In the process, it cached the names and addresses of the eecs.berkeley.edu and berkeley.edu name servers (plus eecs.berkeley.edu's IP address). Now if a resolver were to query our name server for the address of baobab.cs.berkeley.edu, our name server could skip querying the root name servers. Recognizing that berkeley.edu is the closest ancestor of baobab.cs.berkeley.edu that it knows about, our name server would start by querying a berkeley.edu name server, as shown in Figure 2-16. On the other hand, if our name server had discovered that there was no address for eecs.berkeley.edu, the next time it receives a query for the address, it could simply respond appropriately from its cache.
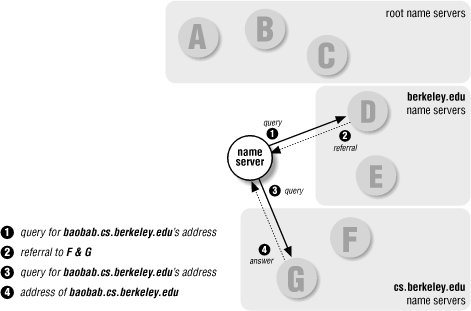
Figure 2-16. Resolving baobab.cs.berkeley.edu
In addition to speeding up resolution, caching obviates a name server's need to query the root name servers to answer queries it can't answer locally. This means that it's not as dependent on the roots, and the roots won't suffer as much from all its queries.2.7.1. Time to Live
Name servers can't cache data forever, of course. If they did, changes to that data on the authoritative name servers would never reach the rest of the network. Remote name servers would just continue to use cached data. Consequently, the administrator of the zone that contains the data decides on a time to live, or TTL, for the data. The time to live is the amount of time that any name server is allowed to cache the data. After the time to live expires, the name server must discard the cached data and get new data from the authoritative name servers. This also applies to negatively cached data; a name server must time out a negative answer after a period, too, in case new data has been added on the authoritative name servers.Deciding on a time to live for your data is essentially deciding on a trade-off between performance and consistency. A small TTL helps ensure that data in your zones is consistent across the network, because remote name servers will time it out more quickly and be forced to query your authoritative name servers more often for new data. On the other hand, it tends to increase the load on your name servers and lengthen resolution time for information in your zones.
A large TTL shortens the average time it takes to resolve information in your zones because the data can be cached longer. The drawback is that your information will be inconsistent for a longer time if you make changes to your data on your name servers.
But enough of this theory -- you're probably antsy to get on with this. There's some homework necessary before you can set up your zones and your name servers, though, and we'll assign it in the next chapter.
|  | |
| 2.6. Resolution |  | 3. Where Do I Start? |
